Text-guided image editing involves modifying a source image based on a language instruction and, typically, requires changes to only small local regions. However, existing approaches generate the entire target image rather than selectively regenerate only the intended editing areas. This results in (1) unnecessary computational costs and (2) a bias toward reconstructing non-editing regions, which compromises the quality of the intended edits. To resolve these limitations, we propose to formulate image editing as Next Editing-token Prediction (NEP) based on autoregressive image generation, where only regions that need to be edited are regenerated, thus avoiding unintended modification to the non-editing areas. To enable any-region editing, we propose to pre-train an any-order autoregressive text-to-image (T2I) model. Once trained, it is capable of zero-shot image editing and can be easily adapted to NEP for image editing, which achieves a new state-of-the-art on widely used image editing benchmarks. Moreover, our model naturally supports test-time scaling (TTS) through iteratively refining its generation in a zero-shot manner.
Our project introduces an innovative two-stage training framework for Next Editing Prediction (NEP). In the first stage, we develop RLlamaGen, a novel text-to-image (T2I) model designed for arbitrary-order full image generation and zero-shot local editing, enabling flexible and precise image creation. In the second stage, we reframe image editing as a next editing-token prediction task, simplifying the learning process to focus solely on regeneration. This approach enhances efficiency and significantly improves editing quality. Additionally, we explore test-time scaling behaviors by integrating NEP into an iterative refinement loop, optimizing performance and output quality.
To address LlamaGen’s limitation of generating image tokens solely in raster scan order, we extend it to create RllamaGen, which supports generating image tokens in any user-specified order, enabling flexible, arbitrary-order generation. To add order awareness to the model, following σ-gpts and RAR, we learn an extra sequence of positional embeddings, which is shuffled based on a random order to define the generation sequence. For each input image token, the positional embedding corresponding to the next token in the assigned order is added.

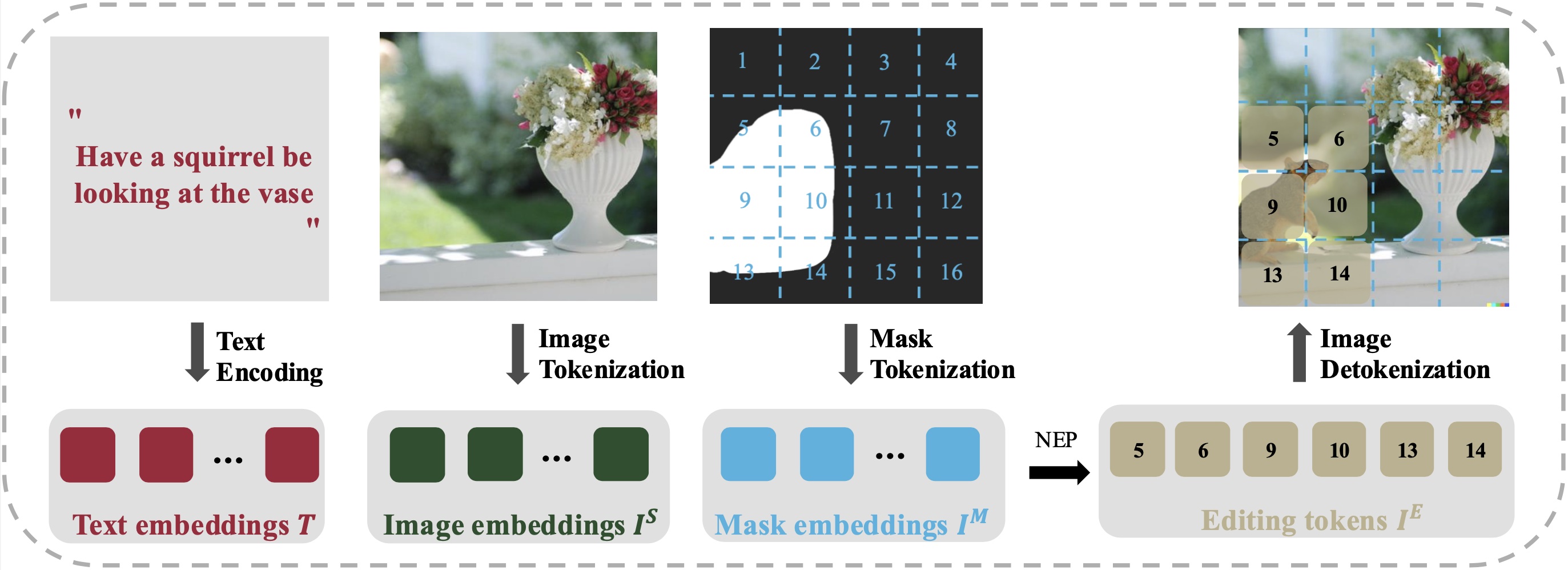
NEP leverages three types of conditioning for region-based editing: 1) text instructions tokens, 2) source images tokens, and 3) editing region masks tokens. The tokenization of text instructions and images remains consistent with the pre-training stage. Editing region conditioning sequences are derived from a pixel-level mask. We firstly patchify the pixel-level editing mask by max-pooling each non-overlapping sliding window. Subsequently, we flatten the patched mask into a sequence. The masking sequence is tokenized by querying a two-sized codebook comprising an editing embedding and a non-editing embedding

NEP can be employed to support test-time scaling by integrating it into a self-improving loop. In each refinement step, prior to NEP, a revision region is proposed. Existing image reward models such as ImageReward usually produce a single value for the full image. To obtain token-level dense quality scores, we calculate Grad-CAM values regarding the critic model (i.e., CLIP-ViT-B/32). These values reflect each token’s contribution to the overall image quality score, measured by a reward model. Positions that correspond to the K lowest scores are identified as the revision regions. During revision, we adopt NEP to regenerate tokens in this region, conditioning them on the remaining high-quality tokens. After NEP, a reward model evaluates whether the revised image surpasses the original, determining whether to accept or reject the revision. To further improve quality, for NEP, we apply a rejection sampling strategy, regenerating tokens at the revision positions in multiple random orders and selecting the revision with the highest quality score. This approach demonstrates strong scaling potential, suggesting that effective revision of initial generations can significantly enhance performance.
